
对话式语音 AI
桌面对话 · 工业语音 · 智能家居 — 端侧多语言对话能力
端侧拾音 + 本地 ASR / TTS,端到端 0.3–0.5 秒响应;按场景挑算力档次,按距离挑拾音方案,无需依赖云端即可获得多语言对话与声音克隆能力。
场景说明
基于现有边缘设备组合,提供"端侧拾音 + 本地 ASR / TTS + 多语言对话"的成套能力,覆盖桌面对话、工业语音控制、智能家居等场景。优先用现成模组快速落地,必要时也可在硬件层面做定制以匹配整机形态。


端到端低延迟
- 端到端 0.3–0.5 秒响应,云端方案难以做到
- 一次硬件投入,后续无按量调用费用
- 长稳无抖动,对话节奏不被网络左右

多语言开箱即用
- 主流多语言识别开箱即用
- 多档音色可选:机器音 / 模拟音 / 真人音
- ~10s 样本即可声音克隆,复刻专属音色

本地处理多重收益
- 仅回传文字,省云端音频流量与带宽
- 语音不出端,符合行业隐私与合规要求
- 不依赖云服务,无地域 / 限流 / 服务下线风险
- 断网弱网仍可完成对话核心链路
场景详情

多语言识别 · 同声传译 · 自然合成
端侧实现多语种识别、实时翻译与自然语音合成。可在桌面设备、会议终端、导览机等形态上落地双向对话与跨语种交流。
核心优势
- 多语言识别:主流语言开箱即用
- 同声传译:边听边译,端到端 0.3–0.5 秒延迟
- 音色分档:机器音 / 模拟音 / 真人音,按预算选择

多语言识别
主流多语言开箱可用,覆盖中英日韩西法德等出海主销语种。

同声传译
边听边译低延迟输出,跨境会议 / 外宾接待 / 文旅导览皆可用。

音色与人设
多档音色按预算选择;克隆 IP 音色 ~10s 样本即可上线。

用语音完成设备控制与现场录入,降低操作门槛
在仓储、车间、机房等现场,端侧语音可替代复杂界面与扫码工具,让一线工人通过自然语言完成出入库登记、设备点检、巡检表单填报、危险事件播报。本地 ASR 输出结构化文字,可对接 WMS / MES / IoT 平台。
核心优势
- 降低操作门槛:自然语言替代复杂界面 / 扫码 / 工单 App
- 弱网可用:本地 ASR,仅文字回传不依赖现场带宽
- 结构化输出:识别结果直接进 WMS / MES / 工单系统

仓储出入库
喊单核对货号 / 数量,结构化文本直接回写 WMS。

设备点检
工人口播设备状态,AI 自动落入点检表单与异常告警。

现场巡检播报
巡检表单语音填报;危险事件实时语音回传指挥中心。

唤醒即响应 · 本地控制 · 声纹个性化
XIAO ESP32S3 做低功耗唤醒前端,触发 AI 盒子启动 ASR-TTS 流水线;声纹识别区分不同成员的偏好;对接 Matter / HomeAssistant / 米家等本地协议执行控制。指令本地处理,断网不影响日常使用。
核心优势
- 毫安级唤醒前端:ESP32S3 ESP-SR 常驻,电池可用月计
- 声纹个性化:家庭成员区分,配置个人偏好
- 本地控制:与 Matter / HomeAssistant / 米家等本地协议打通

低功耗唤醒
ESP32S3 端侧检测唤醒词后再启动主机,整机更省电。

声纹识别成员
本地声纹库匹配家庭成员,自动加载个人场景偏好。

本地 IoT 编排
对接 Matter / HomeAssistant / 米家,云断也能控家。
部署与选型
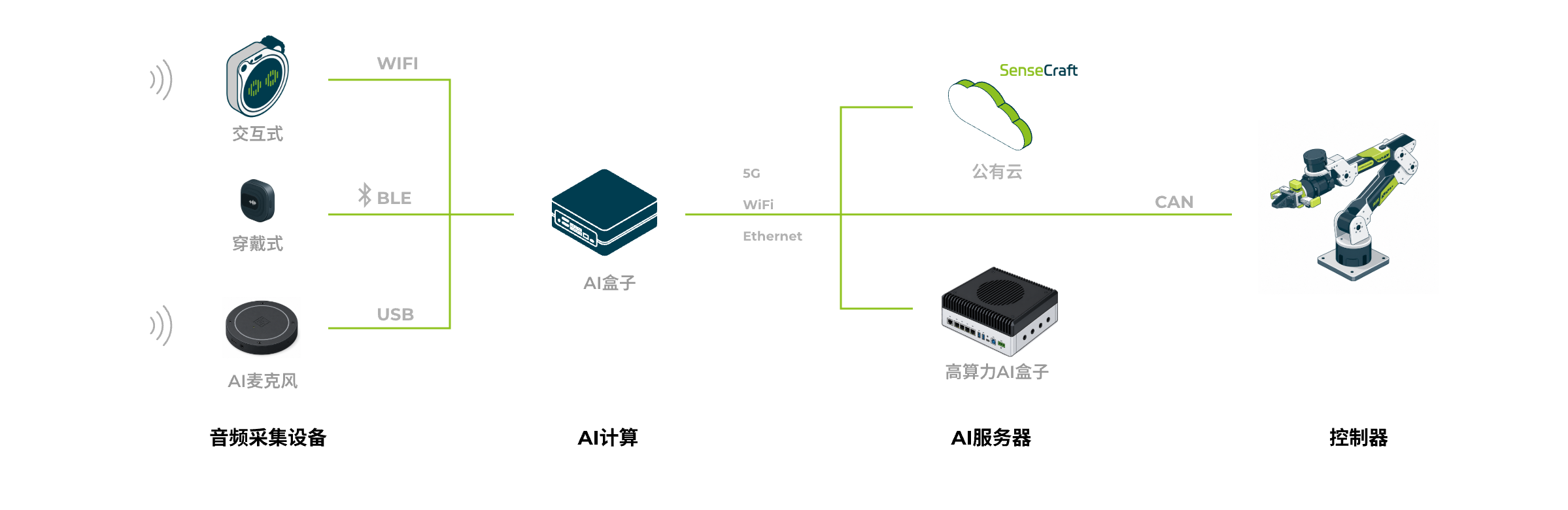
三种架构形态:纯前端 / 混合 / 大模型一体
语音方案的算力放在哪,决定整机能力上限与单台 BOM。常见落地拆成 3 类:
核心优势
- 纯前端方案(ESP32S3):低功耗常驻,仅做唤醒 / 简单命令词;客户自有上位机或纯前端 IoT 设备使用
- 混合方案(前端 + 语音盒子 + 远端 AI):边缘做唤醒 / ASR / TTS,复杂语义和 LLM 走远端;性价比与扩展性最好
- 大模型方案(前端 + 大 AI 盒子):单台 Jetson 跑完整 ASR + TTS + 本地 LLM;隐私 / 离线 / 合规要求最高
| 产品 | 档次 | 准确度 | 支持的语音能力 | 并发 | 试听音色 | 参考价 |
|---|---|---|---|---|---|---|
 XIAO ESP32-S3 Sense XIAO ESP32-S3 Sense | 唤醒前端(板载麦克风) | — | 唤醒词 / 命令词 | — | — | ~$10 |
 reRouter CM4 reRouter CM4 | 入门级 | 基础 | 单语种本地转录 | — | 机器音 | $200–300 |
 reComputer AI R2130-12 reComputer AI R2130-12 | 入门级 | 中等 | 单语言对话 | 单路 | 模拟音 | ~$339 |
 reComputer RK3576 reComputer RK3576 | 单机版 | 好 | 多语言对话 + 本地 LLM* | 单路 | 模拟音 | ~$139 |
 reComputer RK3588 reComputer RK3588 | 单机版 | 好 | 多语言对话 + 本地 LLM* | 单路 | 模拟音 | ~$199 |
 reComputer J3011 reComputer J3011 | 专业级 | 好 | 多语言对话 | 2 路 | 模拟音 / 真人音 | ~$599 |
 reComputer J4012 reComputer J4012 | 专业级 | 好 | 多语言对话 + 本地 LLM | 2–3 路 | 模拟音 / 真人音 | $800–900 |
 reComputer J5012 reComputer J5012 | 旗舰级 | 优 | 多语言对话 + 高级 LLM | 高并发 | 真人音 | ~$2,000 |
按场景能力挑算力盒
AI 算力盒按"能跑哪些语音能力"分档。下表列出档次、准确度、能跑什么、并发与试听音色档及价位(麦克风与扬声器选型见下个 Tab)。*RK 系列本地 LLM 需搭配 1282 AI 加速扩展卡(附件)。
核心优势
- 只做唤醒 / 命令词 → 唤醒前端,~$10 一体
- 单机版高性价比 → RK 系列:多语言对话 + 本地 LLM,单路运行、模拟音
- 专业级真人音 → J 系列:J3011 真人音可选、支持 2 路并发;J4012 加本地 LLM、支持 2–3 路并发
- 高并发 + 高级 LLM → J5012 旗舰级,单机跑完整链路
| 产品 | 类型 | 芯片 | 拾音 距离 | 识音 角度 | 内置 功放 | 核心算法 |
|---|---|---|---|---|---|---|
 reSpeaker Lite reSpeaker Lite | 线形 双麦 | XMOS XU316 | 3m | 180° | 5W | AEC · DoA |
 reSpeaker XVF3800 reSpeaker XVF3800 | 圆形 四麦 | XMOS XVF3800 | 5m | 360° | 5W | AEC · DoA · Multi-beamforming |
 reSpeaker Flex Circular-4 reSpeaker Flex Circular-4 | 圆形 四麦 | XMOS XVF3800 | 5m | 360° | 10W | AEC · DoA · Multi-beamforming |
 reSpeaker Flex Linear-4 reSpeaker Flex Linear-4 | 线形 四麦 | XMOS XVF3800 | 5m | 180° | 10W | AEC · DoA · Multi-beamforming |
reSpeaker 系列三大核心优势
核心优势
- ① 优秀的硬件拾音能力 专为嵌入式场景设计的硬件结构,从物理层面隔离噪声干扰,配合阵列排布实现 DOA 声源定位,拾音效果在同类产品中有明显优势。
- ② 板载 AI 声学算法 基于 XMOS 芯片板载运行 AEC 回声消除、降噪、波束成形等声学算法,对原始音频实时处理后再输出,前端即可输出干净语音,降低后端识别误差。
- ③ 开放的生态系统 固件与 SDK 向开发者开放,支持基于 SDK 自主调节参数,不依赖 Seeed 做二次开发。兼容 XIAO ESP32S3、Raspberry Pi、Jetson 及所有支持 USB / I²S 的平台,可灵活接入已有硬件架构。
联系我们
获取方案参考设计与产品选型支持。